
Abstract
The k-nearest neighbour (kNN) problem appears in many different fields of computer science, such as computer animation and robotics. In crowd simulation, kNN queries are typically used by a collision-avoidance method to prevent unnecessary computations. Many different methods for finding these neighbours exist, but it is unclear which will work best in crowd simulations, an application which is characterised by low dimensionality and frequent change of the data points. We therefore compare several data structures for performing kNN queries. We find that the nanoflann implementation of a k-d tree offers the best performance by far on many different scenarios, processing 100,000 agents in about 35 milliseconds on a fast consumer PC.
Test environments
Some test environments are depictured below.
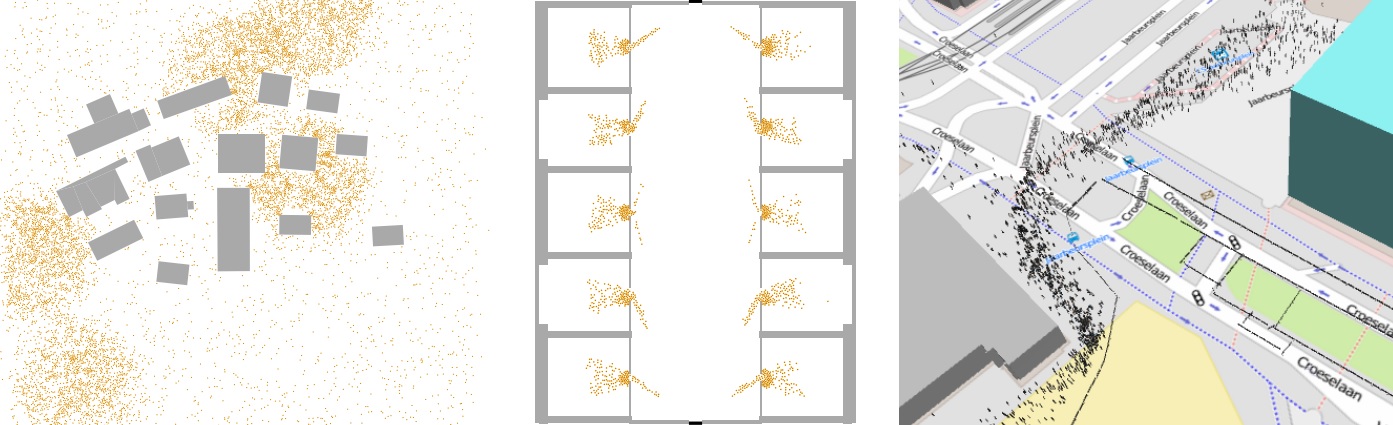
Some of the different test scenarios: clustered distribution, evacuation scenario, and the Tour de France scenario.
References
-
Jordi Vermeulen, Arne Hillebrand and Roland Geraerts. A Comparative Study of k-Nearest Neighbour Techniques in Crowd Simulation. Computer Animation and Virtual Worlds. Volume 28, Issue 3-4. CASA 2017, Seoul - South Korea, May 22-24, 2017.


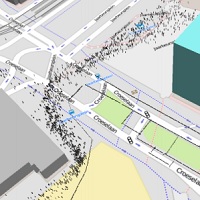
Trajectory data used in our experiments
We used the following trajectory data (in total 4.1GB) in our comparative study.
Each file consists of the following data (in binary format):
- Bounding box of the environment (xmin, xmax, ymin, ymax): 4x8 bytes interpreted as doubles
- For each time step(*):
- The number of agents: 4 bytes interpreted as integer
- For each agent:
- Agent ID: 4 bytes interpresed as integer
- X- and Y-coordinates, 2x8 bytes interpreted as doubles
(*) All file names that embody the word 'combine' represent trajectories that have been sampled 16 times per second. The others have been sampled 10 times per second.



