Visual exploration of software code duplication
During the maintenance of large software systems, code duplicates (also called code clones) appear. These are fragments which contain largely similar, but not identical, source code. When numerous, code duplicates can cause enormous maintenance problems, such as difficult testing, portability problems, and code which is hard to understand.
Good code duplication analysis methods need to meet several criteria:
- efficient processing of code bases of millions of lines
- insensitivity to identifier renaming, comments, and formatting
- independence on the programming language and style
- simple and intuitive presentation of the identified duplicates
Visual exploration of code duplicates
We are exploring a new way to analyze code duplicates. Following the visual analytics principle, we integrate the duplication detection pass with detailed views on the duplicated source code, duplication metrics (statistics), and a global view of duplication relation between files, in a single interactive tool. The tool allows users to extract duplicates, identify files having the largest amount of duplication, get a close look at individual duplicated lines of code, and identify duplication relations between several files, all in a simple way.
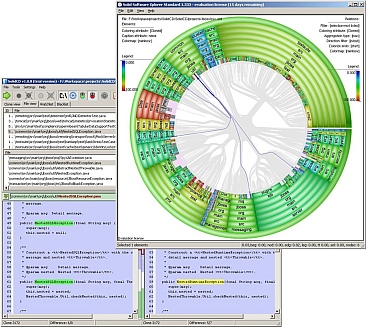
To visualize duplications between files, we extend the hierarchical edge bundles technique used also for software dependency analysis. The image above shows a snapshot of code duplication in a C# project. We see that there are many duplications. The component with most duplications is easily identifiable, being marked in red.
Implementation
An implementation of the duplication tool that scales to code bases of millions of lines is freely available here for research use.
To install this tool, follow the instructions of the installation wizard. Next, use this license file.
Important: This license is provided strictly for educational use. It CANNOT be used in any commercial-related activity.
Publications
See papers 152 and 186 here.